|
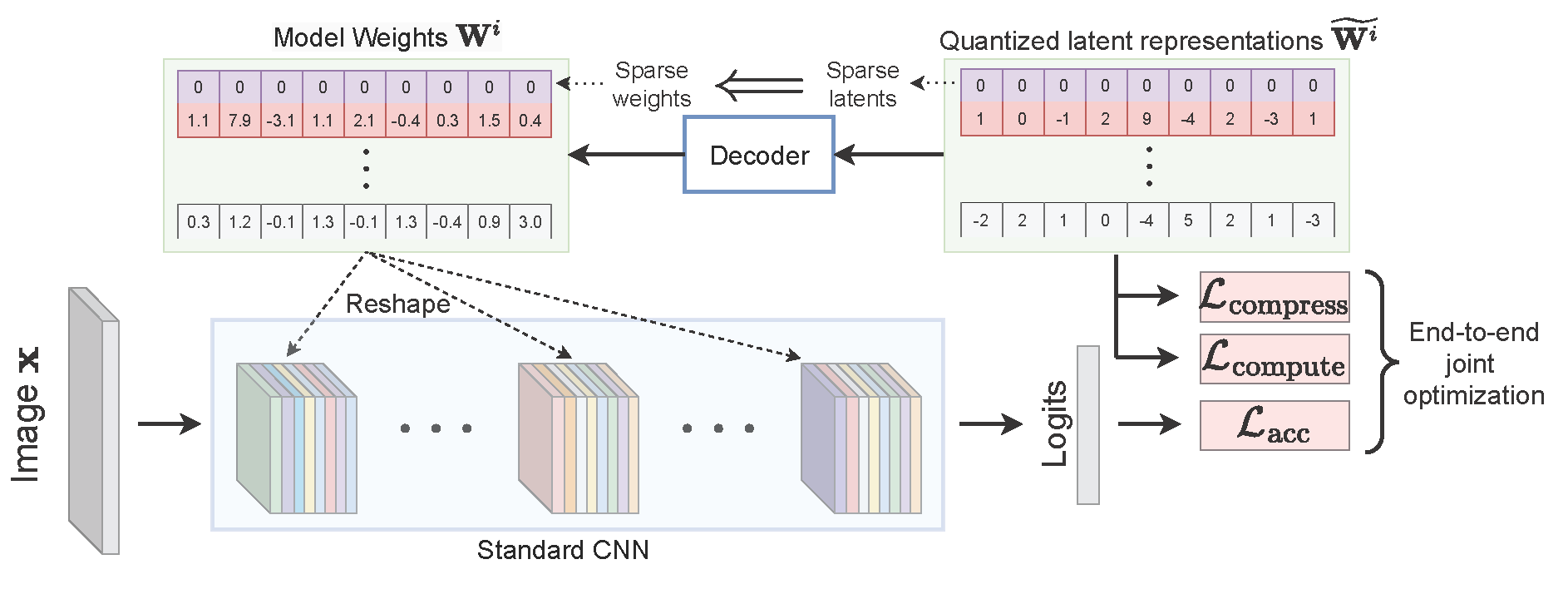
We introduce LilNetX, an end-to-end trainable technique for neural networks that
enables learning models with specified accuracy-compression-computation tradeoff.
Prior works approach these problems one at a time and often require postprocessing or multistage training. Our method, on the other hand, constructs a
joint training objective that penalizes the self-information of network parameters in a latent representation space to encourage small model size, while also
introducing priors to increase structured sparsity in the parameter space to reduce
computation. When compared with existing state-of-the-art model compression
methods, we achieve up to 50% smaller model size and 98% model sparsity on
ResNet-20 on the CIFAR-10 dataset as well as 31% smaller model size and 81%
structured sparsity on ResNet-50 trained on ImageNet while retaining the same
accuracy as these methods. The resulting sparsity can improve the inference time
by a factor of almost 1.86x in comparison to a dense ResNet-50 model.
|